CVE-2019-2215 Study Notes
最近有了点时间,好好看了下CVE-2019-2215的漏洞利用细节,这里记录下来,一方面留着以后再看方便,一方面把自己的理解写出来也是学习的一种方式。
这里问我写的内容可以看成是对Google Project Zero的文章的翻译加上一些个人想法,不过还是推荐看看原文,链接在这里, 因为看的其他的多多少少都有点模糊的地方,没有P0的文章说的详细,这也是我想自己写一个分析的原因。
1. Root Cause
通过阅读对应的issue page和
根据对应的内核Patch(需要注意commit里的内容不太准确),
造成CVE-2019-2215的根本原因在于binder driver内部在收到BINDER_THREAD_EXIT的ioctl后,负责释放对应binder_thread的函数在free binder_thread前没有检查当前binder_thread 是否在epoll中存在引用,从而导致在epoll中存在引用的binder_thread在被释放后依然在epoll中存在一个悬挂指针。当后面epoll因为一些原因尝试删除该已经被释放的binder_thread内部指向的一个waitqueue时出现未定义行为,如Crash(当被free的binder_thread所在的内存已经被分配给其他对象复写破坏时)
利用下面的poc可以在开了KASAN的对应kernel上触发crash
|
|
整个触发时间过程如下图:
可以看到首先通过ioctl 释放binder_thread, 然后程序退出,触发epoll的waitqueue删除操作,从而触发crash。在没打补丁且开了KASAN的对应虚拟机上尝试,可以得到如下的call stack。
从这里就能看到Crash是在remove_wait_queue里面被触发,因为
ep_remove_wait_queue调用了remove_wait_queue, 而remove_wait_queue里面调用了spin_lock_irqsave
|
|
通过分析crash时的log(这里我自己加了printk在binder_thread和ep_remove_wait_queue里面),可以看到Crash时候的binder_thread object的地址是0xffff888046070008,同时在Crash之前的最后一个被释放的eppoll_entry的地址是0xffff88803ab6e6a8。 为了验证binder_thread object对应的fd被加到epoll中后两者的对应关系,我们使用kgdb调试一下kernel,这里具体怎么编译调试的kernel不具体展开,直接看调试打印的变量信息。
可以看到上面crash log里面eppoll_entry.whead刚好就是binder_thread.wait,所以现在可以确定这里ep_remove_wait_queue的whead变量,即remove_wait_queue的参数wq_head就是已经是被释放的binder_thread里的wait,所以当引用wait->lock时指向了一段已经被free的内存,从而在spin_lock_irqsave尝试去写wait->lock时触发KASAN报错。
如果深入检查spin_lock_irqsave,会发现最终调用了_raw_spin_lock_irqsave,其反汇编代码如下,可以看到其中做KASAN检查的地方。这里具体不再展开。
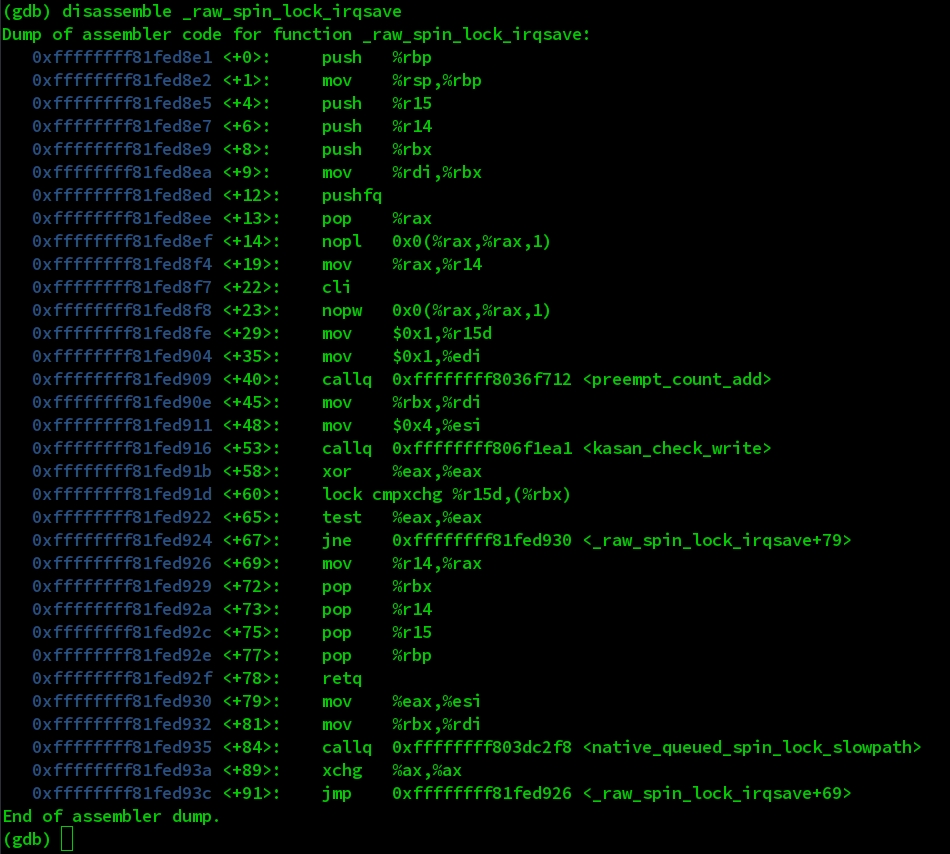
需要注意的是,如果lock本身不是0,那么在这里就会hang住,下面的__remove_wait_queue就无法执行,所以后面在做利用的时候需要做到能保持binder_thread.wait.lock的值为0.
2. Exploit
前面在Root Cause里面已经分析过,之所以被KASAN检测到是因为binder_thread 已经被释放,所以wait指向的内存已经被打上KASAN的标记,但是如果KASAN没有开启,epoll的remove流程会继续走下去,最终走到__list_del。当然,P0的文章里也有提到,如果CONFIG_DEBUG_LIST开启的话,会走不同的代码块,并且有很多check,所以不会有exploit的机会存在,这里只讨论没有开启该flag的情况。
|
|
这里最开始的old就是eppoll_entry.wait,根据代码的解释,即为binder_thread.wait指向的链表上的一个item。
|
|
所以当最终走到__list_del时,里面的unlink操作next->prev=prev通过构造一个虚假的binder_thread 对象在已经被free的binder_thread对应的地址处,就可以完成泄漏内存信息和关键数据修改。
2.1 Preparing
要做kernel里的堆布局,那就必须要对想要覆盖的结构体有足够的了解。这里先看一下binder_thread的代码。
|
|
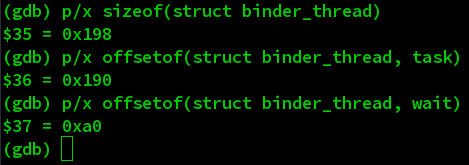
这里我们需要注意的是整个binder_thread的size以及wait和task的偏移。因为最终我们的目的是构造一个和binder_thread类似size的内核变量去复用同一块内存,然后利用删除链表时对wait的操作去获取task的值,然后再次利用unlink去改写addr_limit。通过调试,我们可以得到binder_thread的size为0x198, wait的offset为0xA0, task的offset为0x190.
2.2 Kernel Object Choosing
为了能够成功复写被Free的binder_thread所在的内存区域,我们需要构造一个大小类似的内核结构或者对象,这里选用的是struct iovec.
|
|
通过使用writev和readv,可以用来向指定stream写入存储在不连续内存块(由iovsec[]定义)中的数据,或者从指定stream读出数据写入一些不连续的内存块中。其中iov_base指定每个内存块的地址,iov_len描述每个内存块的size。
使用iovec的其好处在于iov_base和iov_len都是可控的,只要绕过传入内核时对iov_base做的是否在userspace的校验,往后的任意修改都不会有iov_base必须是指向userspace address的校验。
|
|
这里addr_limit的offset是和机器architecture相关的,上面提供的是针对arm64的对应结构的截图,可以看到task_struct的第一个field为thread_info,addr_limit是在thread_info的0x8偏移处,所以我们在拿到task_struct的地址后,0x8 offset处即为addr_limit。
2.3 Leaking Task_Structure
现在和目标结构题相关的信息,需要注意去bypass的点,以及具体利用unlink的点我们已经大概清楚:
- binder_thread 的size为0x198
- wait 的offset为0xa0
- wait.lock的值必须为0,否则执行流无法走到unlink处
- task 的offset为 0x190
- 这里我们要leak前次binder_thread的task数据,所以我们在overlap的时候不能覆盖到0x190之后的内容。
- wait 的offset为0xa0
- arm64下addr_limit位于task_struct 的0x8处
- iovec的size为0x10
- iovec.base 必须是指向用户地址,否则不能通过传入kernel时的校验
所以为了能有较大几率在内核复用被释放的binder_thread使用的内存,我们需要
准备一个大小类似的iovec array,再加上我们不能覆盖想要leak的前一个binder_thread.task的内容,所以我们需要准备0x190 / 0x10 = 0x19 个iovec,即iovec[25],而且为了能利用wait去实现unlink,所以iovec[0xa0 / 0x10]处要准备上符合要求且精心构造的数据。这里借用P0博客里的图片展示内存对应关系:
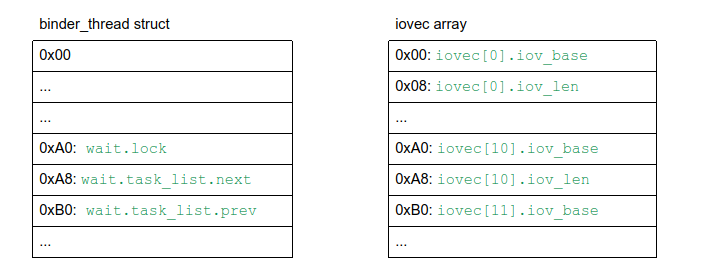
在确定大概的对应的关系后,我们还需要让相关内存块的内容满足如下要求:
wait.lock需要为0x0iovec.base必须指向用户空间地址wait.task_list.next和wait.task_list.prev在unlink后都会指向wait.task_list.next
为了实现这个要求,P0在原文中使用了如下的数据来填充关键内存块:

相关代码如下:
|
|
iovec[0]到iovec[9]里的内容都是0x0,对于iovec.base和iovec.len都为0x0的元素,在写入和读出时将直接跳过。
对于iovec[10](对应于wait.lock和wait.task_list.next)和iovec[11](对应于wait.task_list.prev),则填入我们精心构造的数据: 为了满足wait.lock(32bit)为0x0且iovec.base指向用户空间,我们需要申请一个低32bit全为0的用户空间内存块,P0原文里申请的是0x100000000UL,刚好满足上述两个要求。
前面已经分析过,在触发unlink时,binder_thread.wait是head,对应于eppoll_entry.whead,而要删除的元素对应于eppoll_entry.wait,而要删除的元素是当前list里面唯一的元素,所以删除后留下的只有eppoll_entry.whead本身,此时head的next和prev都指向其自己。这里直接引用P0的解释图:
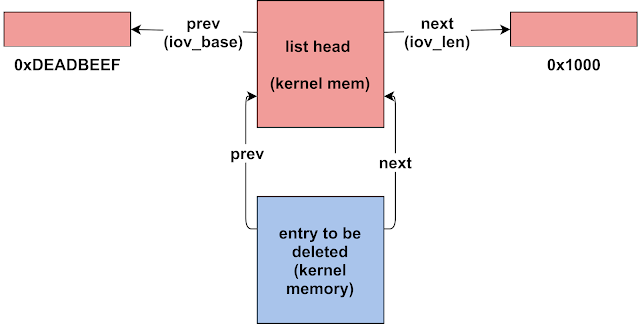
unlink前,
|
|
unlink时,根据list_del的代码:
|
|
则unlink完成后,内存布局如下:
这里需要注意的是,在开始触发unlink前,会先在父进程用writev阻塞管道(前面已经把pipe的buffer设置为0x1000)
|
|
- 在unlink前,父进程
writev将iovec[10]指向的dummy_page_4g_aligned内存块的0x1000内存读出写入pipe,而后阻塞。 - 而后子进程触发unlink,改写
iovec[11].iov_base为指向&iovec[10].iov_len的指针,接着使用readv读出已经被writev写入pipe的dummy_page_4g_aligned内容 - 此时
writev读取iovec[11].iov_base的内容(此时已被改写为指向binder_thread.wait.task_list的指针),父进程再次调用readv,成功读出被释放从binder_thread.wait.task_list开始的0x1000字节内容到buffer - 此时
buffer + 0xE8即为task指针值。从而成功拿到当前进程的task_struct结构体地址(wait偏移为0xa0,task偏移为0x190,wait.task_list在wait + 0x8处,所以distance为0x190-0xa0-0x8 = 0xe8)
|
|

unlink关键利用代码如下:
|
|
2.4 Overwrite addr_limit
前面已经拿到了进程的task_struct,下面将会重复类用与上面相似的iovec[25]布局去尝试改写addr_limit。 与leaking task_struct相比,不同之处在于本次不再用writev,而使用recvmsg去接收iovsec[25],阻塞等待,直到write写入数据篡改addr_limit:
利用socket,同样可以如读写iovec数组:
|
|
这里只需准备好msghdr结构体,而后利用recvmsg等待数据写入iovec[25]即可。
|
|
再看本次unlink前使用的内存布局:
|
|
本次布局和前次略有不同:
iovec[10].iov_len = 1,这里在后面会在创建socket后首先写入1 Byte到dummy_page_4g_aligned指向的内存,令write下次写入时将从iovsec[11].iov_base指向的内存块开始写入数据。
|
|
接下来触发unlink漏洞:
|
|

这里借用P0 blog里的图。左边是unlink后的内存布局。
首先依然是利用unlink去改写iovec[10].iov_len和iovec[11].iov_base,使其指向iovec[10].iov_len。
而后就是本次攻击的重点,右边部分,该布局是
|
|
写入second_write_chunk后的效果。
|
|
首先,此时write会从iovec[11].iov_base指向的内存开始写入数据,并且写入数据的size为0x28 Bytes。而此时iovec[11].iov_base指向iovec[10].iov_len所在内存,即偏移为binder_thread + 0xa8处。从而将从0xa8偏移处,依次写入second_write_chunk中的数据。
|
|
以上刚好是0x28 Bytes的数据,而current_ptr正是我们已经通过第一次leak tast_struct 得到的地址,所以此时的iovec[12].iov_base就指向了addr_limit所在的内存。同时iovec[11].iob_base指向的内存(从iovec[10].iov_len开始的0x28 Bytes)已经写完。所以此时write会将接下来的数据写入iovec[12].iov_base指向的内存(也即存储addr_limit的内存),即
|
|
到这里,就成功篡改了addr_limit的限制,后面即可读写kernel任意内存。
2.5 Full Poc
这里把 P0提供的完整poc贴在这里,方便查阅。
|
|
3. Conclusion
CVE-2019-2215的问题在于binder这类提供通过设备文件访问其功能的内核驱动没有处理好其销毁过程中和epoll联动部分(同步销毁其在epoll中可能存在的引用)。针对此类问题,可以尝试扩展到其他类似的驱动模块上进行代码审计,审计点在于check是否同样存在没有同步销毁其于epoll中的引用的问题。
4. Reference
- https://googleprojectzero.blogspot.com/2019/11/bad-binder-android-in-wild-exploit.html
- https://bugs.chromium.org/p/project-zero/issues/detail?id=1942
- https://bugs.chromium.org/p/project-zero/issues/attachmentText?aid=414885
- https://dayzerosec.com/posts/analyzing-androids-cve-2019-2215-dev-binder-uaf/